Data analysis
練習專案四:找出章魚里 3
數據可視化
概念驗證
- 計算全國得票率 A
# 計算全國得票率 A total_votes = votes_by_village['sum_votes'].sum() country_percentage = votes_by_village.groupby(['candidate_id' ,'candidate'])['sum_votes'].sum() / total_votes vector_a = country_percentage.reset_index()['sum_votes'].tolist()
- 計算村鄰里得票率 B
# 計算各村鄰里總票數 village_all = votes_by_village.groupby(['county' ,'town' ,'village'])['sum_votes'].sum().reset_index() # 合併 merge_list = ['county' ,'town' ,'village'] merged = pd.merge(votes_by_village, village_all, left_on=merge_list, right_on=merge_list, how='left') # 計算村鄰里得票率 B merged["village_percentage"] = merged['sum_votes_x'] / merged['sum_votes_y']
- 計算餘弦相似度
# 計算餘弦相似度 pivot_df['vector_a_dot_vector_b'] = (vector_a[0] * pivot_df['1']) + (vector_a[1] * pivot_df['2']) + (vector_a[2] * pivot_df['3']) pivot_df['length_vector_a'] = pow(((vector_a[0] ** 2) + (vector_a[1] ** 2) + (vector_a[2] ** 2)), 0.5) pivot_df['length_vector_b'] = pow((pivot_df.iloc[:,3:6] ** 2).sum(axis=1), 0.5) pivot_df['cosine_similarity'] = pivot_df['vector_a_dot_vector_b'] / (pivot_df['length_vector_a'] * pivot_df['length_vector_b'])說明:
vector_a_dot_vector_b = A · B
length_vector_a = ||A||
length_vector_b = ||B||
cosine_similarity = (A · B) / (||A||·||B||)
- 清理資料
cosine_similarity_list = ['county' ,'town' ,'village','1','2','3','cosine_similarity'] cosine_similarity_df = pivot_df[cosine_similarity_list].copy() # 排序 sort_values_list = ['cosine_similarity','county' ,'town' ,'village'] cosine_similarity_df = cosine_similarity_df.sort_values(sort_values_list, ascending=[False, True, True, True]) # 建立 rank cosine_similarity_df = cosine_similarity_df.reset_index(drop=True).reset_index() cosine_similarity_df["index"] = cosine_similarity_df["index"] + 1 # 修改欄位名稱 column_names_to_revise = {"index": "rank", '1': "candidate_1", '2': "candidate_2", '3': "candidate_3"} cosine_similarity_df = cosine_similarity_df.rename(columns=column_names_to_revise)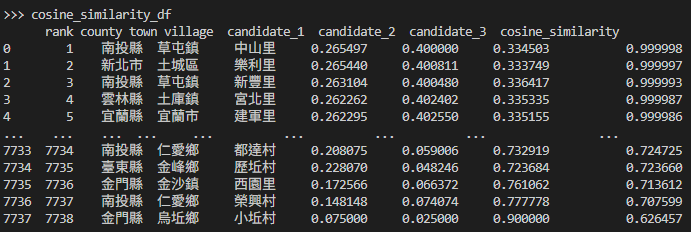
- 建立查詢函數
# 篩選 def filter_county_town_village(df, county_name, town_name, village_name): county_condition = df["county"] == county_name if len(county_name) > 0 else True town_condition = df["town"] == town_name if len(town_name) > 0 else True village_condition = df["village"] == village_name if len(village_name) > 0 else True return df[county_condition & town_condition & village_condition]
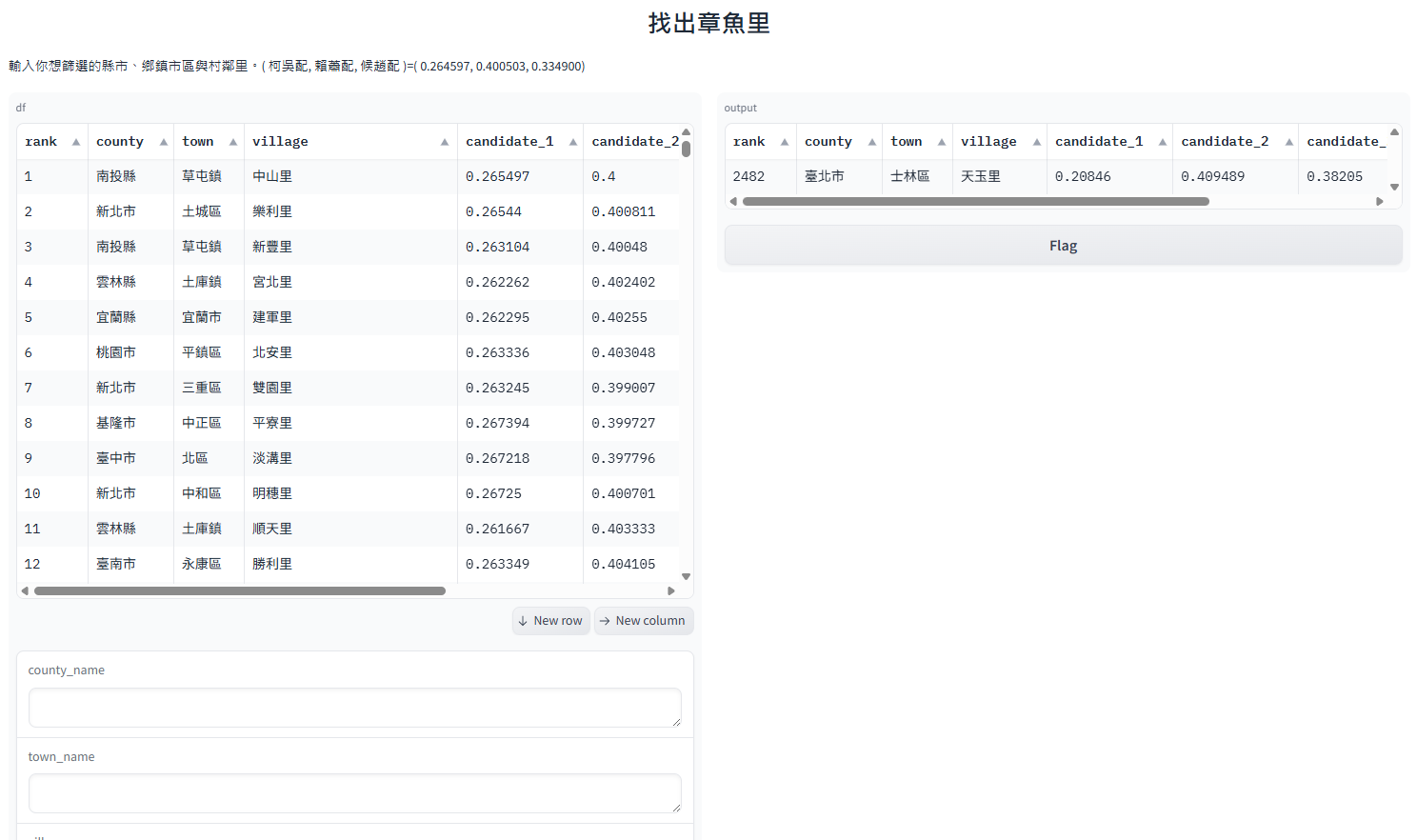
可視化成品
- 採用
gradio展示成品,可以點選連接 成品 參考成品。country_percentage, gradio_dataframe = self.create_gradio_dataframe() # 調整小數點到第6位 gradio_dataframe_list = ['candidate_1', 'candidate_2','candidate_3', 'cosine_similarities'] gradio_dataframe[gradio_dataframe_list] = gradio_dataframe[gradio_dataframe_list].round(6) # 拆分各候選人比例 ko_wu, lai_hsiao, hou_chao = country_percentage interface = gr.Interface(fn=filter_county_town_village, inputs=[gr.DataFrame(gradio_dataframe), 'text', 'text', 'text'], outputs='dataframe', title='找出章魚里', description=f'輸入你想篩選的縣市、鄉鎮市區與村鄰里。( 柯吳配, 賴蕭配, 候趙配 )=( {ko_wu:.6f}, {lai_hsiao:.6f}, {hou_chao:.6f}) ') # 啟動網頁是伺服器,關閉 Ctrl + Z or interface.close()。 interface.launch()