練習專案三:資料科學家的工具箱 5
完整分析流程與洞察
在這篇文章中,我將分享我在進行 Kaggle ML & DS Survey 資料分析專案時所採用的探索性資料分析(EDA, Exploratory Data Analysis)流程。
剛開始自主分析時的確相當混亂,幾乎沒有任何進展。後來開始釐清問題,並參考他人是如何分析的,意外接觸到「探索性資料分析」這個概念,便以此作為切入點展開分析。
本篇前半段主要介紹 EDA 的基本概念,後半段則紀錄實際的分析過程。我重新整理並撰寫分析的每個步驟,除了幫助自己釐清邏輯,也強化記憶。畢竟從完成專案到回頭重寫這篇文章,時間其實並不長,才過不久卻發現思緒已經模糊,因此特別想記錄下來。
在重新整理筆記的過程中,我發現不少邏輯錯誤,透過釐清原意與修正問題,補足了許多原本遺漏或模糊的觀念。對我來說,這是一個非常有幫助的反思與學習過程。因此,本篇某種程度上是寫給自己看的筆記,可能顯得有些冗長、不夠精煉,但若你對分析的邏輯與思考方式有興趣,也歡迎參考。
本篇將依照「資料處理 → 探索分析 → 目標釐清 → 主題洞察 → 策略反思與視覺化」的邏輯來呈現整體成果。
由於我是自行學習的初學者,內容中可能仍有錯誤。我已盡力查證與修正,但無法保證所有觀念都完全正確,若有不妥之處,也請不吝指正,感謝。
探索性資料分析(EDA, Exploratory Data Analysis)介紹
- 在資料分析中,EDA 是「理解資料、找出問題與機會」的起點:
- 釐清資料結構與邏輯:資料來自哪裡?有什麼欄位?格式是否一致?
- 辨識與處理異常:是否有缺值?不合理值?欄位意義是否混亂?
- 觀察變數分布與趨勢:什麼是常見值?哪些變數有分布偏斜?
- 提出分析假設與方向:我們可以從資料中回答哪些問題?有哪些有趣的關聯?
- 這些步驟幫助我們在後續建模、視覺化與報告時,做出更精準且具意義的分析。
-
EDA 分析流程
- Step 1. 資料結構理解
- 使用
.head()、.info()初步了解欄位與型態 - 確認資料量、缺失比例與欄位命名邏輯
- 使用
- Step 2. 資料清理與轉換
- 處理缺值與格式不一致(例如薪資欄位中的區間文字)
- 建立跨年度欄位對照表,統一欄位命名與順序
- 將區間轉為數值(如:“30-39” → 35)
- Step 3. 欄位分類與變數篩選
- 將欄位區分為:類別型(如性別、國家)與數值型(如年齡、薪資)
- 建立技能數量、國家地區分類欄位,幫助後續分群
- Step 4. 單變量分析(Univariate Analysis)
- 觀察各變數的分布:如薪資級距、職稱類型、人數比例
- 使用 bar chart、histogram 呈現結果
- Step 5. 雙/多變量分析(Bivariate/Multivariate)
- 交叉觀察兩變數關係,如:地區 vs 薪資、技能 vs 職位
- 使用氣泡圖、堆疊長條圖、boxplot 呈現不同組合
- Step 6. 擬定分析主軸與策略
- 根據觀察結果,決定要聚焦的主題與切入方式
- 例如:薪資落差與國家/技能關聯、技能變化趨勢與學習資源影響
- Step 1. 資料結構理解
探索性資料分析分析過程。
從這裡開始將進入整個分析流程,若對細節不感興趣,可直接跳轉至 下一篇。
Step 1. 資料結構理解
使用 .head()、.info()、.describe()、.isnull() 等方法確認資料的基本結構,了解資料欄位、檢查缺失值與異常值。這裡使用的是課程中第一次清洗後的資料。
-
df.head():快速預覽前幾筆資料。
>>> df.head() ividuals are respons... 0 2291 surveyed_in question_index question_type question_description response response_count 0 2020 Q21 Single Choice Approximately how many individuals are respons... 0 2291 1 2020 Q21 Single Choice Approximately how many individuals are respons... 1-2 2645 2 2020 Q21 Single Choice Approximately how many individuals are respons... 10-14 692 3 2020 Q21 Single Choice Approximately how many individuals are respons... 15-19 300 4 2020 Q21 Single Choice Approximately how many individuals are respons... 20+ 2247
-
df.info():快速檢視資料。
顯示整個 DataFrame 的結構、欄位名稱、資料型別(dtype)、非空值數量(Non-Null Count)與記憶體使用情況。
-
為什麼這樣做:
- 快速確認哪些欄位有「缺失值」。
- 檢查資料型別是否正確(例如數字是否被誤當作文字)。
- 確認資料筆數是否與預期相符。
>>> df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 13725 entries, 0 to 13724 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 surveyed_in 13725 non-null int64 1 question_index 13725 non-null object 2 question_type 13725 non-null object 3 question_description 13725 non-null object 4 response 13725 non-null object 5 response_count 13725 non-null int64 dtypes: int64(2), object(4) memory usage: 643.5+ KB
欄位 資料型別 說明 surveyed_in int64 ✅ 沒問題,年份是整數。 question_index object ✅ 題號,文字型態合理。 question_description object ✅ 題目,文字型態合理。 response object ✅ 回覆,文字型態合理。 response_count int64 ✅ 出現次數是整數。 ✅ 所有欄位皆無缺值
-
-
df.isnull():再次檢查是否有遺漏值
- 這個方法能清楚列出每個欄位的缺失值筆數。
>>> df.isnull().sum() surveyed_in 0 question_index 0 question_type 0 question_description 0 response 0 response_count 0 dtype: int64
-
df.describe():簡單的描述統計
對數值欄位(如 int、float)產出統計摘要,包括:總數、平均值、標準差、最小值、四分位數與最大值。
- 用途:
- 發現極端值(如 response_count 過高)。
- 評估資料分布與離散程度。
>>> df_describe 2020 2021 2022 count 4723.000000 5004.000000 3998.000000 # count(總數):每個欄位中非缺失值(非 NaN)的數量。 mean 177.742748 238.049361 206.326413 # mean(平均值):每個欄位的平均值。 std 886.520151 1200.215385 1098.017375 # std(標準差):用來衡量數據的分散程度(標準差越小,表示資料值越接近樣本平均數。標準差越大,表示資料值分佈越廣,某些值離樣本平均數越遠。)。 min 1.000000 1.000000 1.000000 # min(最小值):每個欄位的最小值。 25% 1.000000 1.000000 1.000000 # 25%(第一四分位數):數據中的 25% 分位值。 50% 1.000000 2.000000 1.000000 # 50%(中位數或第二四分位數):數據的中位數,也稱作 50% 分位值。 75% 12.000000 15.000000 14.000000 # 75%(第三四分位數):數據中的 75% 分位值。 max 15789.000000 21860.000000 18653.000000 # max(最大值):欄位的最大值。
如何判斷 標準差: 標準差 / 平均值 = 變異係數 CV < 0.1(10%):變異小(資料穩定) CV ≈ 0.2~0.3:中等變異 CV > 0.5:變異很大(高度不穩定)
- 用途:
-
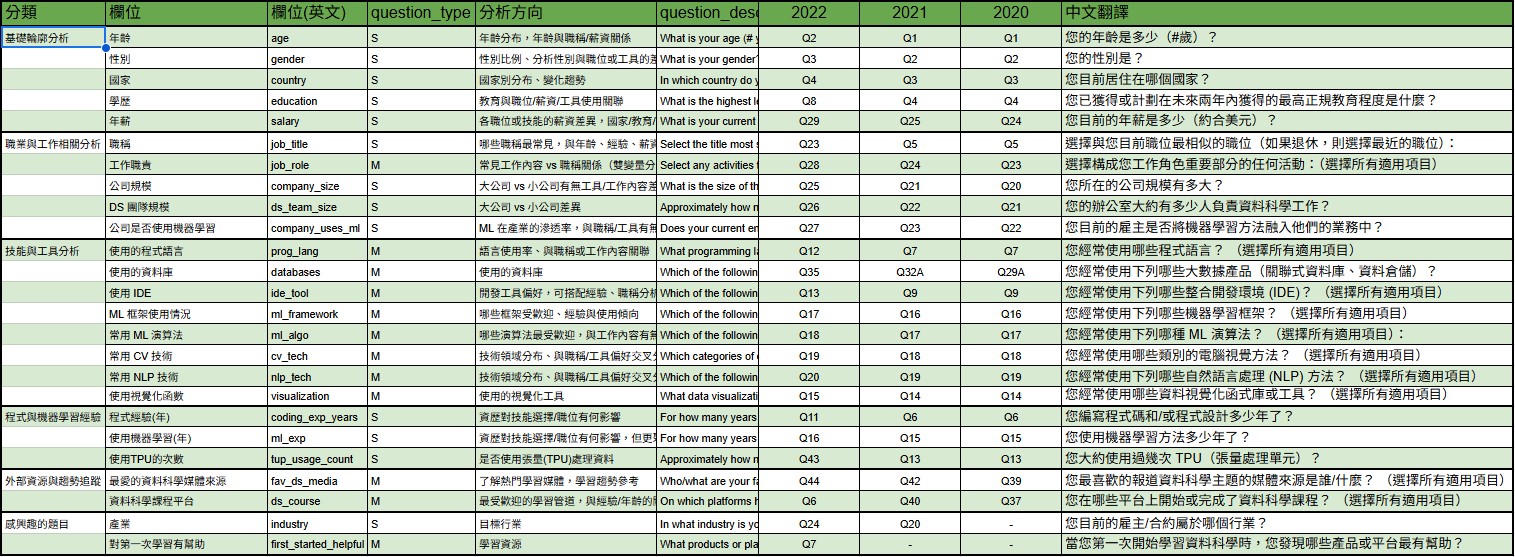
建立跨年度題目對照表:
kaggle_question_reference_table不同年度的題號不一致(如 Q6 在 2020 是「年資」,在 2022 則是「程式經驗」),需對應。
- 好處
- 對齊不同年份的相同題目。
- 避免混淆欄位。
- 可支援跨年度視覺化分析。
- 好處
Step 2. 分類欄位與數值欄位:
- response 資料表 (全部回覆資料):
- 數值型變數:
- respondent_id:使用者編號
- surveyed_in:年份
- 類別型變數:
- question_index:題目編號
- response:回答內容(主要分析對象)
- 數值型變數:
- questions 資料表:
- 數值型變數:
- surveyed_in:年分
- 類別型變數:
- question_index:題目編號
- question_type:單複選
- question_description:題目內容
- 數值型變數:
- aggregated_responses 檢視表:
- 數值型變數:
- surveyed_in:年份
- response_count:回覆總數
- 類別型變數:
- question_description:題目內容
- response:回答內容(主要分析對象)
- 數值型變數:
- kaggle_question_reference_table 資料表 (找出共通題目):
- 類別型變數:
- question_description:題目內容
- 2020:2020年題目標號
- 2021:2021年題目標號
- 2022:2022年題目標號
- 類別型變數:
Step 3. 單變量分析(Univariate Analysis)
-
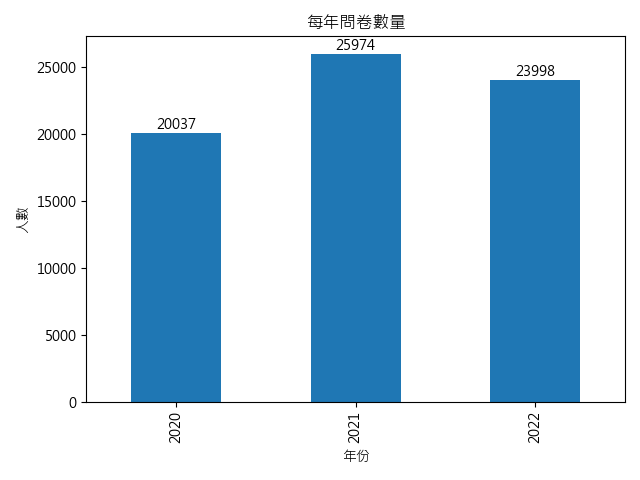
surveyed_in(年份):
- 目標:掌握每年問卷數量,評估樣本規模。
- 說明:能幫助辨識不合理狀況,例如問卷數為 500 卻有超過 1000 筆回覆。
-
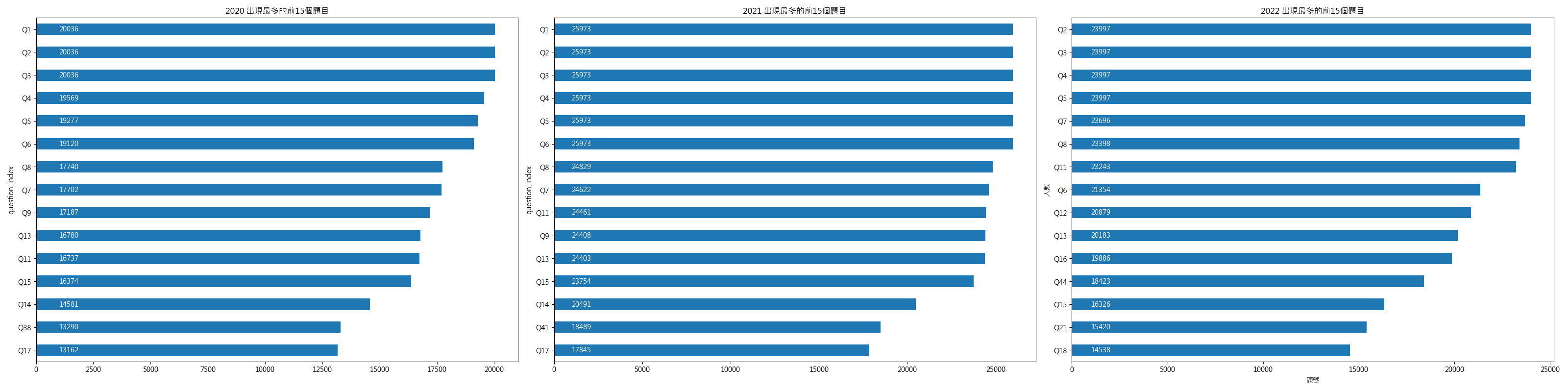
question_index(題目代號):看哪些題目最常出現
- 目的:了解各題目出現頻率。
- 說明:有助於觀察熱門題目、趨勢變動、新增題目或冷門題目。
-
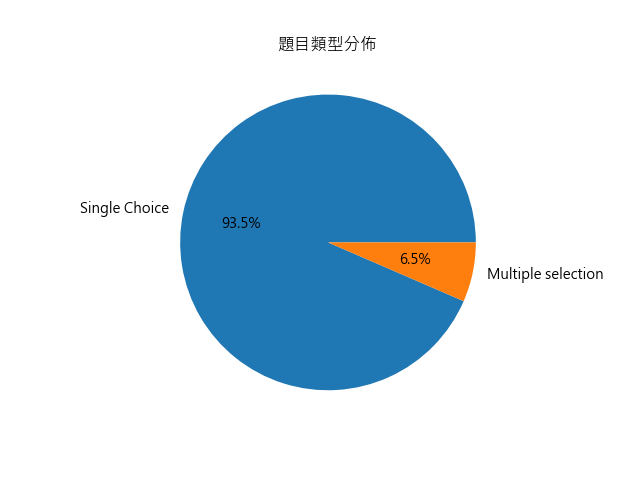
question_type(題目類型):類別型變數,單選 vs 多選 數量
- 目的:統計單選題與多選題的數量。
- 說明:本資料中約 93% 為單選題,6% 為多選題。
-
response(選項內容):類別型變數,出現頻率最高的選項(限制特定題目)
- 目的:分析回覆選項的出現頻率,找出關鍵選項。
- 說明:初步分析應聚焦於「出現次數高」的選項。
- 範例:找出出現次數最多的選項(最高為 21860 筆),並對應該選項的題目 Q7 進行深入觀察。

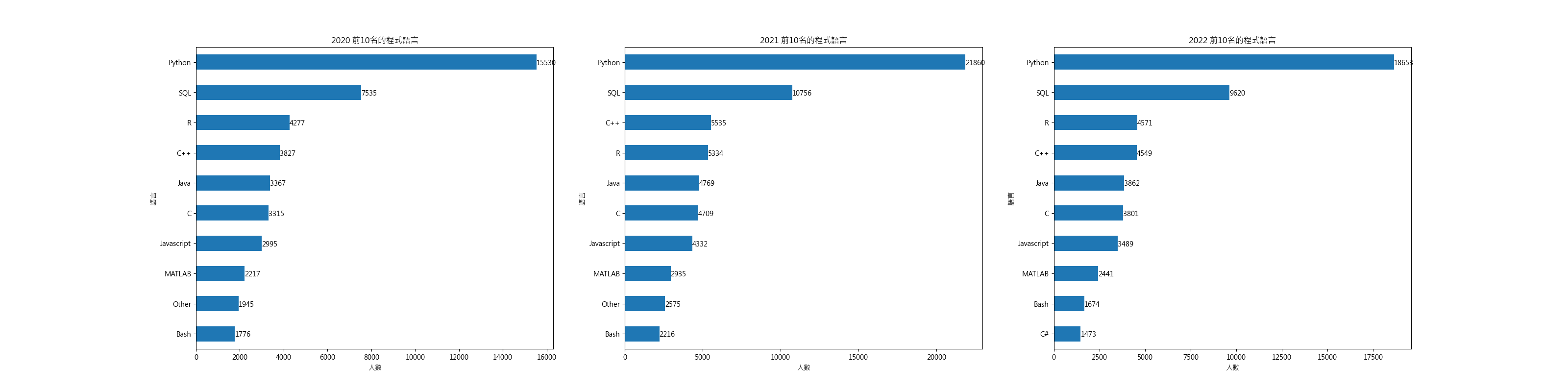
Step 4. 擬定分析主軸與策略
-
檢視過基礎資料後,我發現幾個待解決的問題:
- 題號與回覆資料需要標準化。
- 若想分析特定族群,需要先建立群組。
- 目前目標不夠明確,需進一步釐清分析方向。
-
釐清目標
-
- 明確定義分析目標
- 我問自己:「我想從這份資料中解答什麼問題?」
- 這次的主要目標是:
了解資料分析師的實際樣貌與技能需求,進而修正錯誤認知、規劃學習方向。
- 探索面:他們都在做什麼?需要哪些技能?
- 策略面:這職位適合我嗎?值得花時間投入嗎?
- 這次的主要目標是:
-
- 拆解具體子題
- 將總體目標拆解為可執行的分析子題,例如:
- 常見技能有哪些?
- 不同國家或年資的薪資有何差異?
- Data Analyst 和其他職位的技能需求有何不同?
- 哪些技能與高薪相關?
-
- 確認分析範圍與資料 - 重新整理資料範圍。
- 聚焦 2020–2022 年共通題目(約 25 題),並依主題分類如下:
- 基礎輪廓:年齡、性別、學歷、國家、薪資。
- 技能與工具:程式語言、資料庫、ML 框架、ML 演算法、視覺化工具、IDE、CV、NLP。
- 工作與職責:職稱、工作內容、公司規模、DS 團隊規模、ML 使用情況。
- 經驗:程式經驗、ML 經驗、使用TPU的次數。
- 學習資源:學習平台、媒體來源。
- 特殊題目:產業分類、初學工具。
-
- 收集資料與清理
- 統一欄位命名與回覆格式(清理 None、錯別字)
- 將類別回覆轉為結構化資料(如將程式語言轉為 One-hot 編碼)
- 篩選分析對象(例如排除學生或無業者)
-
- 分析與視覺化
- 使用 Power BI 進行資料探索,包含:
- 薪資分佈、職稱熱力圖、技能佔比長條圖、年度趨勢變化等。
目的:讓資料背後的故事更具體、直觀易懂。
-
- 洞察 → 回到目標
- 分析過程中不斷檢視:「這些結果是否能回應我一開始的問題?」
- 若能,則彙整出具體結論並規劃後續行動,例如:
- 哪些技能是一定要學的?(如 Python、Scikit-learn)
- 是否值得投入這個職涯方向?
- 下一步是補足哪些能力?申請哪些職位?
-
- 總結:
- 分析目標:了解資料分析師的實際樣貌與技能需求,進而修正錯誤認知、規劃學習方向。
- 目標族群:以 “Data Analyst”、“Business Analyst”、“Data Scientist”…等,相關職業為主。
- 分析方向:基礎輪廓分析、技能與工具分析、工作內容與公司環境、學習資源與趨勢追蹤、薪資與經驗分析。
-
主題式分析與洞察過程。
1. 資料驗證
資料清理是整個分析中最耗時的部分,包含命名標準化、資料驗證、型別轉換與欄位分群。有些資料表(如 country_area、salary_order、prog_lang_skill_group 等)是分析需求建立的,接下來會一一說明這些表的設計原因與用處。
- 在分析前要先檢查資料的狀況 (Step 1. 資料結構理解),因為所拿到的資料不一定是自己處理過的版本,需要再檢查一次「格式、缺失、異常值」。
2. 基礎輪廓分析
-
目的:瞭解整體樣貌與背景
-
發現問題。
- 年薪資料異常嚴重:有大量樣本標示極低薪資,與常理不符,尤其即使在低收入國家也應超過 $1,000 美元。
資料中 0 佔比高達 28%,0–999 佔比約 13%。
- 年薪與經驗矛盾:存在「程式經驗 1–3 年」卻標示「年薪超過 50 萬美元」的極端樣本,判斷為誤填。
- 資料多為文字格式:如 salary: 0–999,coding_exp: 1–3 years,需轉為數值方能進行比較與篩選。
- 年薪資料異常嚴重:有大量樣本標示極低薪資,與常理不符,尤其即使在低收入國家也應超過 $1,000 美元。
- 處理方式。
- 建立
salary_order資料表- 將年薪區間轉為中位數(例如:0–999 → 500),利於數值計算與排序。
- 建立
country_area資料表,加入 GDP 和 最低薪資,驗證 年薪 資料的正確性。- 建立各國GDP資料
資料來源:Gapminder 中的 Fast Track、檔案名稱:ddf–datapoints–gdp_pcap–by–country–time.csv
- 依 GDP 分群為四類:低收入 / 中低 / 中高 / 高收入
- 加入各國 匯率 、 貨幣單位 與 最低工資(最低工資轉換為美金)
匯率標準:2022 年最後一週
資料來源:ILO(國際勞工組織)、檔案名稱:EAR_4MMN_CUR_NB_A-20250529T0752.csv
- 建立各國GDP資料
- 建立
-
視覺化。
- 國家分布(country)
- 印度與美國樣本最多,印度佔比接近三成。
- 年齡 (age)
- 多數集中在 22–44 歲,其中 25–29 歲佔比逾 24%。
- 顯示資料分析領域多為轉職或職場初中期族群。
- 性別分布 (gender)
- 男性佔比約 79%,女性與非二元性別佔比明顯偏低。
- 學歷 (education)
- 約 80% 擁有學士或碩士學位。
- 顯示資料分析職位通常要求高等教育背景,碩士學歷有助於晉升或起薪。
- 年薪 (salary)
- 初始樣本中有超過一半(52%)標示年薪低於 $5,000,包括 0 與 0–999,清理後僅剩 9725 筆有效資料。
本圖表為清理後的資料分布,排除了低於法定最低薪資、極端高薪但無經驗等明顯異常樣本。
年薪區間以中位數換算為美金,並以 ILO 公布的最低工資與 Gapminder 的 GDP 分組做為清理標準,確保樣本具備一定信度。
- 國家分布(country)
- 總結與思考。
- 樣貌輪廓:以 年輕(25–29 歲)、碩士學歷、男性 為主,地區則以 印度與美國為最大樣本來源。
- 年薪為最需清理的欄位,誤填、遺漏與極端值比例高,清理完後年薪僅 9725 筆為有效樣本,作為薪資後續分析基礎。
- 後續需將不同經濟發展程度與地區文化背景納入解釋框架,例如:薪資應該在「相對經濟環境下」來比較,而非直接以全球統一標準比較。
3. 技能與工具分析
-
目的:觀察產業中最常見的工具與技術,作為學習參考
-
視覺化。
-
使用 IDE (ide_tool)
- Jupyter Notebook 曾是主流 ,但在之後明顯下滑。
- VSCode 使用率逐年上升,可能是因為擴充功能元多更為方便。
-
經常使用的程式語言 (prog_lang)
- Python 為絕對主流,適用於各類資料處理與建模工作。
- SQL 比預期的要少,顯示未必是分析師必要技能。
- R 語言 雖使用率較低,但在統計與 A/B 測試場景具獨特優勢,適合有意深入統計者進一步學習。
-
經常使用的資料庫 (databases)
- 僅約 40% 受訪者回應使用過資料庫,推測多數人主要以 靜態資料檔案(如 CSV) 進行分析。
- 對於初學者而言,資料庫操作雖非必備,但若進入企業環境將成為重要技能。
-
經常使用的視覺化工具 (visualization)
- 有近 80% 的曾經使用過,顯示圖形化的能力為分析師的核心技能。
-
ML 框架 (ml_framework)
- 超過 70% 受訪者使用過至少一種 ML 框架,顯示預測與建模能力已成為資料分析核心技能。
建議:初學者可從 Scikit-learn 開始,若對深度學習或 NLP 有興趣,再深入 TensorFlow/Keras 或 HuggingFace。
-
常見演算法 (ml_algo)
- 邏輯回歸、決策樹、Gradient Boosting → 簡單好用、適合大部分任務
- 神經網絡(如 CNN、RNN) → 偏向進階應用(如影像、時間序列)
- 以下表格列出各類演算法的特性與初學者建議程度:
技術類別 解釋 初學者是否常用 Linear/Logistic Regression 預測數值或分類(例如房價預測、是否購買),經典入門模型。 ✅ 非常常見 Decision Trees / Random Forests 用「一連串條件判斷」來分類或預測,易解釋、入門必學。 ✅ 非常常見 Gradient Boosting Machines (xgboost, lightgbm) 目前很多競賽冠軍都愛用的強大預測模型。 ✅ 常見(尤其在實務) Dense Neural Networks (MLPs) 基本的深度學習神經網路,處理結構化數據的基本神經網路。 ✅ 常見 Convolutional Neural Networks (CNN) 常用於影像處理的神經網路。 ✅ 影像任務常見 Recurrent Neural Networks (RNN) 處理時間序列或文字,已較少使用。 ❌ 現在用 transformers 替代多 Transformer Networks (BERT, GPT) 處理 NLP、也有用於 CV 等任務,現今主流架構。 ✅ 越來越普遍
-
常用 CV (cv_tech):常用的圖片處理
- 使用率偏低,最多也僅有 17% 使用 Image Classification。
- 推測 CV 技術屬特定領域(如醫療、製造業)所需,非資料分析師的共通能力。
-
NLP 技術 (nlp_tech):自然語言:神經網絡
- 僅 15% 受訪者曾經使用過自然與,這意味 NLP 屬於特定領域應用,非所有分析師日常工作所需。
-
-
總結與思考。
- 核心必學:Python、Scikit-learn、資料視覺化(Matplotlib、Seaborn)、VSCode/Jupyter
- 加分技能:SQL、資料庫連接、R 語言、統計知識
- 建議:不用一開始就學全部,先打好資料處理與分析基礎(Python、視覺化、ML),再依目標補足統計、商業思維或進階技術。
4. 工作內容與公司環境
-
目的:了解職責與產業狀況
-
發現什麼?
- 2022 年
job_title欄位的空值比例高達近 50%。後來發現「學生」被拆分為獨立題目,可能是為了區分是否為在職進修。 - 原始資料中超過半數屬於非從業者或職稱不明,例如學生(34%)、其他(7%)等,這些樣本未必屬於本次研究的目標分析群體。
- 2022 年
-
如何處理。
- 將 2022年 的
學生資料與job_title合併。 - 建立群組欄位
job_title_group,將職稱進行分類以聚焦分析目標,篩選後剩餘樣本數為 22,616 筆。- Data-related:如 Data Analyst、Data Scientist、ML Engineer 等。
- Exclude:如 學生、其他、空值、未就業。
- 將 2022年 的
-
視覺化。
-
職稱
- 資料顯示最多的職稱為 Data Scientist,其次為 Software Engineer 與 Data Analyst,2022 年 Data Analyst 首度超越 Software Engineer。這可能反映出業界需求趨向應用層資料人才的增加。Business Analyst 與 Data Engineer 等職位也持續成長中。
-
常見職稱與工作職責(多選題長表)
- 資料分析相關職位的主要職責為「分析並理解資料以影響產品或商業決策」(約佔 50%),這是資料分析師的核心工作。其次是資料基礎建設與機器學習應用相關任務(各約佔 25–30%),顯示部分分析師也需兼具工程與研發能力。約 20% 的人表示曾參與。
-
公司規模
- 公司規模分布均勻,大公司與小型新創皆有資料分析師職位,顯示該職業於各類型組織中皆有需求。2022 年起大型企業略為增長,可能反映產業數位轉型的趨勢。
-
DS 團隊規模
- 最常見的團隊規模為「1–2人」與「20+人」,顯示資料團隊規模呈兩極化:一方面是獨立分析師在小型企業中運作,另一方面則是成熟企業中組成完整的資料科學團隊。中間規模(3–9人)亦具穩定比例,可能為資料部門發展中的常態型態。
-
公司是否使用 ML
- 僅有約 20% 的受訪者表示公司有穩定使用 ML 於生產環境,另有近 30% 表示正處於探索階段,這顯示,即便從業者擁有相關技能,實際部署 ML 至生產環境的情境仍偏少,企業端多處於試驗性質或尚未導入階段。
-
所在行業 (目標行業)
- 資料分析職位最多集中在「科技/電腦」(28%),其次為「會計金融」與「學術教育」(各約 11%),其他如醫療、製造、零售、線上服務則約各佔 4–5%。顯示雖科技業為主體,但跨產業應用正逐步擴展。
-
-
總結與思考。
- 資料分析職位在各產業皆有需求,尤以科技、金融、教育產業為主。常見職稱包括 Data Scientist、Data Analyst 與 Software Engineer,近年 Data Analyst 有明顯上升趨勢。工作職責以「分析資料以影響決策」為主,其次為機器學習與資料基礎建設,顯示跨職能需求。企業端導入機器學習仍以探索階段為主,實際落地比例不高。
5. 學習資源與趨勢追蹤
-
目的:找到主流學習管道
-
視覺化。
-
入門學習資源分析:
- 資料顯示,初學者最常使用的學習管道為線上課程(62%)、Kaggle(56.7%)、YouTube(54.6%)。這顯示目前資料學習資源以「數位線上與互動學習」為主,且不再以大學課程為核心。傳統學術課程(僅約 22%)與論壇型社群(如 Reddit)比例明顯較低。
-
學習來源:
- 在資料媒體來源上,YouTube、Kaggle、Blogs(如 Towards Data Science)為主流,三者皆佔 40% 左右。這類內容多為開放式、短時長、即時更新的資訊,反映出資料分析師傾向從社群媒體獲得學習靈感與新知。反觀學術論文、email newsletter 等傳統媒介,佔比逐年下降。
-
學習課程平台:
- Coursera 長期為首選學習平台,但使用率逐年下降(2020 年近 37%、2022 年降至 28%),而 Kaggle Learn 與 Udemy 成為次主力,分別佔約 30%。其他如 DataCamp、edX、LinkedIn Learning 為輔助平台。
- Coursera (40%)、Kaggle (30%)、Udemy (30%)。
-
-
總結與思考。
- 從學習資源的使用分析可看出,資料分析師的學習方式正快速轉變:由過去仰賴傳統教育體制,逐步轉向以 Coursera、Kaggle Learn、YouTube 為代表的數位化、自主學習為主。
- 對初學者來說,線上課程提供完整的基礎建構,Kaggle 可用於強化資料處理與建模實作,而社群平台則是追蹤技術趨勢、獲得靈感的重要來源。善用這些開放學習資源,能有效加速學習曲線與實戰轉換率。
- 對於在職轉職者而言,線上課程、Kaggle、影音與社群平台是最具實用性的學習途徑,能提供快速入門所需的知識與實戰素材。
6. 薪資與經驗分析
-
目的:了解入門門檻與上升空間
-
發現什麼?
- 這段分析主要觀察技能組合、技能數量與程式經驗,是否與職位類型及年薪呈現顯著關聯,所以需要將 技能、經驗 轉為數值。
-
如何處理。
- 建立
prog_lang_skill_group:由於技能是以文字紀錄,所以將 prog_lang 轉換成 One-hot 編碼,方便檢查必要技能、統計技能數。id Python R SQL … skill_count Python_SQL_group 0 1 0 1 … 2 1 - 建立
coding_exp_years_order: 將經驗區間轉為中位數(例如:1-3 years → 4),利於數值計算與排序。
- 建立
-
視覺化。
- 薪資 & 經驗 & 洲別
- 可明顯看出北美與大洋洲的年薪顯著高於其他地區。
- 也能看出隨這經驗的提升,薪水會漸漸提高。
- 年薪 & 技能(數量) & 職稱
- 能明顯的看每個職業所需的技能數量是差不多的,可以做為入門學習的指標。
- 薪資 & 經驗 & 洲別
-
總結與思考。
- 從地區薪資分布來看,北美與大洋洲的從業者年薪遠高於亞洲與南美,落差甚至可達 3–5 倍,顯示地區經濟條件對薪資的直接影響。經驗方面,年資越多的確有助於提高薪資,但亞洲地區整體成長幅度相對緩慢。
- 在技能數方面,大多數職位使用 2–3 種程式語言已足以勝任,技能數量雖有幫助,但並非與薪資呈線性關係。更關鍵的,往往是職位本身與所處產業(如 Data Scientist vs Business Analyst)。
- 這顯示學習策略不應僅追求語言數量,而是結合職位需求、地區特性與經驗深化作為發展主軸。