Data analysis
練習專案三:資料科學家的工具箱 3
數據清理(Data Clean)
資料說明
- 本次的數據清理是以上一篇
《練習專案三:資料科學家的工具箱(二)》中的kaggle_survey.db為基礎,並在後續分析過程中,根據實際需求逐步進行調整與清理,例如:正規化題目與選項、修正錯誤資訊、建立群組等。 - 最終將資料表拆分為以下幾個子資料表:
- kaggle_question_reference_table:統一題號與欄位分類
- responses:所有回覆資料(長表格式)
- responses_single_choice_group:單選題整理與群組資料 (寬表資料格式)
- prog_lang_skill_group:統計各人使用的程式語言數量(多選題轉統計值)
- salary_order:薪資分級與排序
- country_area:將國家對應至洲別
- coding_exp_years_order:將文字敘述的經驗年數進行排序與分群
參考資料:資料分析的七個練習專案:累積個人作品集 由於程式碼較為複雜,此處不提供程式碼,有興趣的讀者可前往我的 GitHub 下載。
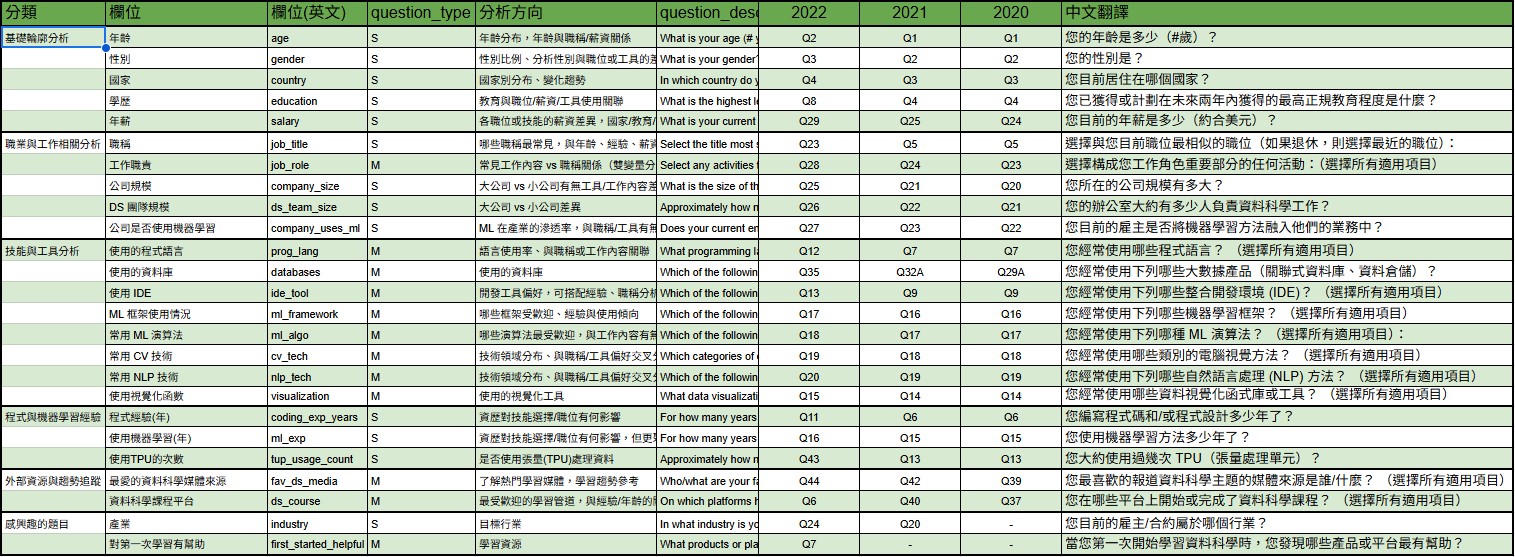
一、kaggle_question_reference_table
- 這張資料表是在分析開始前,為了方便觀察各年度問卷中的共通題目而建立的(初期使用 Excel 編輯)。其主要目的包括:
- 確定主要分析的題目。
- 分類題目類型
- 確認各題的分析方向
- 統一各年度中相同題目的欄位名稱
- 此表是分析初期的重要基礎資料,後續在轉換資料格式、建構分析資料表時,都會參考這張表進行欄位統一與題目篩選。
- 欄位說明:
- 分類: 將題目依主題分類,例如:基礎輪廓分析、技能與工具分析、學習資源與學習經歷…等,用於分組觀察與呈現。
- 排序: 主要用於 Power BI 中標籤順序排序。若無此欄,Power BI 會自動依字母排序,影響視覺呈現的邏輯順序(此欄在其他分析中不一定會用到)。
- 欄位: 為該題設計的中文欄位名稱,方便後續交叉分析與圖表標示使用。
- 欄位英文(col_eng): 統一命名的英文欄位(如
age、salary、ml_algo),可作為資料欄位名稱對應的主鍵。 - question_type: 表示該題是單選(S)或多選(M),遇到多選題時需額外轉為長表進行處理。
- 分析方向: 初步規劃的分析切入點與用途,例如:與工作型態、學習資源、工具偏好等的關聯。
- 2022、2021、2020: 各年度該題目在原始問卷中的編號(如 Q1、Q5 等)。
- question_description: 該題的英文原文描述,保留作為查找或驗證用途。
- 中文翻譯: 自我翻譯的中文題目說明,用於題目分類與理解輔助。
這張表是我在準備分析時所建立的基礎對照表,幫助我統整不同年份的問卷題目。
二、responses
分析完題目後,接下來需進一步清理資料並規劃分析用資料表,以提升後續分析效率與一致性。這樣能避免重複資料造成空間浪費,並透過正規化提升資料的一致性與可維護性。
-
欄位名稱標準化:將不同年份中命名不一致的欄位,統一修改為一致的名稱。
例如:「年齡」在 2022 年題號為
Q2,2021 與 2020 年則為Q1,最終統一命名為age。 -
建立主鍵(Primary Key):重新編排 id,作為唯一識別資料表中每一筆紀錄的主鍵。
-
回覆資料標準化:統一處理不同年份在描述方式、選項數量或順序上的差異。這部分是我在整體清理流程中花費最多時間的階段。
- 我的做法是透過
drop_duplicates對每道題目的回覆進行比對與清查,最後統一為一致的格式。
例如:「使用的 IDE」中,發現有的年份選項為
Jupyter (JupyterLab, etc.),有的則為Jupyter Notebook,實際意義相同,因此將前者統一修改為Jupyter Notebook。 - 我的做法是透過
- 範例:
# 資料標準化函式。 def safe_replace(df, mask, column, mapping): df.loc[mask, column] = df.loc[mask, column].replace(mapping) return df # 查看修改前的唯一值 response_df.loc[response_df['question_index'] == 'country', 'response'].drop_duplicates().tolist() # 進行標準化 mapping = {'United States of America':'USA', 'United Kingdom of Great Britain and Northern Ireland':'UK', 'Hong Kong (S.A.R.)':'Hong Kong', 'Iran, Islamic Republic of...':'Iran', 'Viet Nam':'Vietnam', 'Republic of Korea':'South Korea' } response_df = safe_replace(response_df, response_df['question_index']=='country', 'response', mapping) # 查看修改後的唯一值(驗證修改結果) response_df.loc[response_df['question_index'] == 'country', 'response'].drop_duplicates().tolist() - 發現
salary為文字,需要建立平均數和排序salary_rank、salary_mean。job_title2022年,學生變成單獨一題Q5,發現並無學生是在職人員,因此決定直接將 2022 年的 Q5 合併到 job_title。
三、responses_single_choice_group
- 將單選題獨立整理後,可以將每一題視為一個「分析族群」。在進行多變量分析時(例如折線圖、氣泡圖),這些欄位能作為 圖例(Power BI),用以觀察不同技能、學歷、國家等族群之間的差異。
- 此表額外建立欄位:
job_title_group、salary_group
四、prog_lang_skill_group
- 統計每位受訪者學過的程式語言數量,並將每個語言拆分為獨立欄位,製作成 One-hot 格式,以利後續與年薪進行比較,判斷學習哪些語言可能具有加分效果。
- 此表建立欄位:
count、Python_SQL_group、R_SQL_group、Python_R_SQL_group。
五、salary_order
- 將薪資區間轉為連續數值 ( 例如:
0-999→499.5),便於進行統計或圖表排序。 - 此表建立欄位:
rank、salary_mean。
六、country_area
這個表是花費最長時間處理的。
- 整合國家所屬區域( area )、GDP 與最低薪資資料。
- 建立
gpd_group(GDP_年分)、area- 資料來源:Gapminder,使用的資料集為 Fast Track。
- 檔案名稱:
ddf--datapoints--gdp_pcap--by--country--time.csvddf--entities--geo--country.csv
- 建立
annual_salary(最低薪資年收入)- 資料來源:ILO(國際勞工組織),https://ilostat.ilo.org/data/,關鍵字 Minimum Wages(最低工資)。
- 檔案名稱:
EAR_4MMN_CUR_NB_A-20250529T0752.csv
七、coding_exp_years_order
- 由於問卷中沒有直接詢問「工作年資」,因此以
coding_exp_years作為多變量分析的替代指標。 - 建立欄位:rank(作為 Power BI X 軸排序依據)。
- 將區間資料轉為數值 ( 例如:
1-3 years→2)。