Data analysis
練習專案二:拿破崙征俄戰爭 2
環境設定(Environment Setup)
建立新環境
(base) conda create -n minard_clone python=3.12
檢查環境
(base) conda env list
進入新建力環境
(base) conda activate minard_clone
安裝模組
(minard_clone) conda install pandas
(minard_clone) conda install matplotlib
(minard_clone) conda install basemap
數據準備(Data Preparation)
數據來源(Data Sources)
- 來自 Re-Visions of Minard 的資料
- 是由 York University 的 Michael Friendly 教授建立的教學網站,目的是透過統計資料與軟體,來講解資料視覺化。
- 提供了不同來源資料格式、呈現結果的 Minard 專案(他所稱的 Minard’s Challenge)。
- Mathematica
- SAS/IML
- 練習使用:The Grammar of Graphics 網站所提供的文字檔
- R/ggplot2
數據結構(Data Structure)
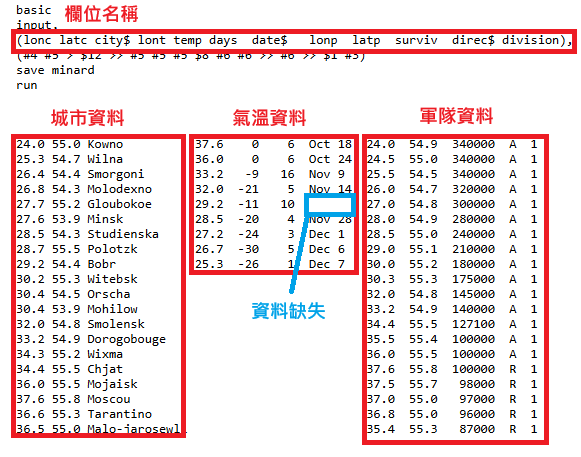
- 將資料分為 3 個部分城市資料、氣溫資料、軍隊資料。
-
城市資料
- lonc, latc:當前軍隊的位置(經度、緯度)。
- city:城市名稱(如果當前位置有城市)。
-
氣溫資料
- lont:經度。
- temp:氣溫(原始資料採用「列氏」溫度)。
- days:天數(間隔幾天)。
- date:日期。
-
軍隊資料
- lonp, latp:軍隊行進過的經緯度(用於繪製軍隊的移動路線)。
- surviv:在該地點的倖存士兵數量。
- direc$:軍隊行進方向:
- A(Advance):前進(入侵俄國)。
- R(Retreat):撤退(從俄國撤退)。
- division:部隊的分隊或編號。
-
數據導入(Data Import)
由於數據是 txt 導入後是以每行為一筆資料,之後需要手動分割。
- 數據外觀、數據清理
- 從外觀可觀察到2個問題需要處理:
- 欄位名稱錯誤:欄位名稱包含特殊符號。
- 氣溫資料缺失:經觀察可從 days 資料反推。
- 從外觀可觀察到2個問題需要處理:
-
開啟檔案
with open("minard_clone/data/minard.txt") as f: lines = f.readlines() -
欄位名稱:
- 導入第2行欄位名稱,分割後發現欄位包含特殊符號,需要正規畫處理。
column_names = lines[2].split()- 數據清理:使用正規化來達成來處理欄位名稱符號問題,提供幾種方法。
# 方法一 column_names_cleaned = [re.sub(r'\W+', '', col) for col in column_names] # \W+ 表示匹配「非字母、數字、底線」的所有字符,並替換為空字串。 # 方法二 column_names_cleaned = [col.strip('(),$') for col in column_names] #方法三 import pandas as pd column_names_cleaned = pd.DataFrame({"name":column_names}).map(lambda x: re.sub(r'\W+', '', x))- 方法一:完全去除特殊符號最通用。
- 方法二:只除特定符號(如 $、,)。
- 方法三:如果數據量很大(幾萬到幾百萬筆)建議使用 Pandas,更快更有效率!
-
載入模組
import re import pandas as pd import sqlite3 -
城市資料
def creata_city_df(self): # 分割資料 column_names_city = list(self.column_names_cleaned.name[:3]) longitudes, latitudes, cities = [], [], [] for df in self.lines[6:26]: long, lat, city = df.split()[:3] longitudes.append(float(long)) latitudes.append(float(lat)) cities.append(city) # 合併資料 city_data = (longitudes, latitudes, cities) # 建立空的 DataFrame,準備填入整理後的數據 city_df = pd.DataFrame() # 將 city_data 的內容對應到相應的欄位名稱 for column_name, data in zip(column_names_city, city_data): city_df[column_name] = data return city_df -
氣溫資料
- 備註:這邊需要處理缺失資料。
def creata_temperature_df(self): # 分割資料 column_names_temp = list(self.column_names_cleaned.name[3:7]) lontvalues, tempvalues, days, dates = [], [], [], [] for df in self.lines[6:15]: lont, temp, day = df.split()[3:6] lontvalues.append(float(lont)) tempvalues.append(int(temp)) days.append(int(day)) # 資料缺失處理 if day == "10": # 這行需要特殊處理,因為資料會將軍隊資料納入。 # ["29.2", "-11", "10", "缺失日期資料" , "27.0", "54.8"]。 dates.append("Nov 24") else: # 由於是以空白為分割點,所以需要將資料重新合併。 # ["Oct", "18"] 日期被分成兩筆資料。 dates.append(df.split()[6] + " " + df.split()[7]) # 合併資料 temp_data = (lontvalues, tempvalues, days, dates) # 建立空的 DataFrame,準備填入整理後的數據 temperature_df = pd.DataFrame() # 將 city_data 的內容對應到相應的欄位名稱 for column_name, data in zip(column_names_temp, temp_data): temperature_df[column_name] = data return temperature_df -
軍隊資料
def create_troop_df(self): # 分割資料,由於資料欄位不同所以,直接倒入最後 5 攔是比要好的選擇。 column_names_troop = list(self.column_names_cleaned.name)[-5:] lonp_values, latp_values, surviv_values, direc_values, ivision_values = [], [], [], [], [] for df in self.lines[6:-3]: lonp, latp, surviv, direc, division = df.split()[-5:] lonp_values.append(lonp) latp_values.append(latp) surviv_values.append(surviv) direc_values.append(direc) division_values.append(division) # 合併資料 troop_data = (lonp_values, latp_values, surviv_values, irec_values, division_values) # 建立空的 DataFrame,準備填入整理後的數據 troop_df = pd.DataFrame() # 將 troop_data 的內容對應到相應的欄位名稱 for column_name, data in zip(column_names_troop, troop_data): troop_df[column_name] = data return troop_df -
導入 SQLite
def create_database(self): # 載入資料 city_df = self.creata_city_df() temperature_df = self.creata_temperature_df() troop_df = self.create_troop_df() # 建立 SQLite connection = sqlite3.connect("minard_clone/data/minard.db") df_dict = { "cities": city_df, "temperatures": temperature_df, "troops": troop_df } for k, v in df_dict.items(): v.to_sql(name=k, con=connection, index=False, f_exists="replace") # v.to_sql(name=資料表名稱, con=檔案位置, index=是否載入 pd 排, if_exists="replace" 若同名檔案存在蓋) connection.close()
備註(Notes)
-
使用 tuple 合併資料:
# 將資料 list 合併為 tuple city_data = (longitudes, latitudes, cities) temp_data = (lontvalues, tempvalues, days, dates) troop_data = (lonp_values, latp_values, surviv_values, direc_values, division_values)-
使用 tuple 的好處。
- 資料安全性:Tuple 是不可變(Immutable)的,防止後續誤修改
- 效能更好:在 zip() 時,Tuple 能提供更快的索引存取,在不需要修改內容的情況下,效能優於 List。
- 內存管理:Tuple 佔用的內存通常比 List 少,當需要處理大量數據時,這能節省資源。
-
總結:Tuple 適用於固定內容且不需要修改的情境,而 List 更適合可變數據。這裡的資料是一組固定的數組合,因此用 Tuple 會更好!
-
-
正規畫補充
-
數據量大時(幾萬到幾百萬筆)
- 建議使用 Pandas(向量化運算)
- Pandas 內部用 Cython(C 語言優化),比 for 迴圈快 數十到數百- 倍。
-
什麼時候 for 迴圈比較好?
-
每次處理的內容都不同(無法向量化) 如果每一筆資料的處理方式不同,Pandas 向量化 可能不適用。
-
複雜的條件判斷
- 如果條件太複雜(例如 if-else 太多),apply() 可能 不比 for 迴圈快。
- 數據量小時(幾百筆以內),寫 for 迴圈更直觀
- 如果只是 10 筆數據,寫 for 迴圈 對效能沒什麼影響,但有時候可能比 apply> () 更容易理解。
-
-
結論:
- 大數據 Pandas 向量化方法(效能最好)
- 小數據 for 迴圈 也可以(影響不大,但 Pandas 可讀性更高)
- 當數據量大時,避免 for 迴圈,否則會變慢!
-