Data analysis
練習專案一:復刻兩百個國家、兩百年、四分鐘 2
啟動環境與安裝模組的指令
建立新環境
(base) conda create -n gapminder_clone python=3.12
檢查環境
(base) conda env list
進入新建力環境
(base) conda activate gapminder_clone
安裝模組
(gapminder_clone) conda install pandas
(gapminder_clone) conda install matplotlib
(gapminder_clone) conda install plotly
數據準備(Data Preparation)
數據結構
- 人均 GDP:ddf–datapoints–gdp_pcap–by–country–time.csv。
- country:國家代碼。
- time:年份。
- gdp_pcap:人均 GDP。
- 預期壽命:ddf–datapoints–lex–by–country–time.csv。
- country:國家代碼。
- time:年份。
- lex:預期壽命。
- 人口數:ddf–datapoints–pop–by–country–time.csv。
- country:國家代碼。
- time:年份。
- pop:該年該國的 總人口數。
- 地理資訊:ddf–entities–geo–country.csv。
- country:國家代碼。
- name:國家名稱。
- world_4region:洲別。
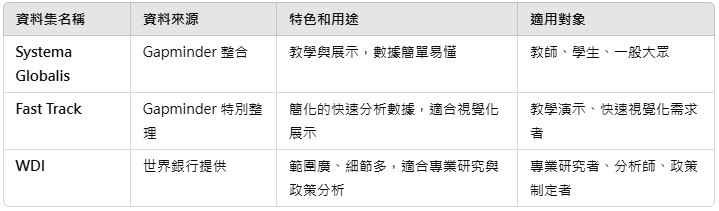
- 資料來源:Gapminder 提供,主要用於描述和分析全球的社會、經濟、環境等多方面統計數據。
- Systema Globalis
- Fast Track <- 這次使用的資料
- World Development Indicators
數據導入
- 開啟檔案。
# 載入當案名稱。 file_name = ["ddf--datapoints--gdp_pcap--by--country--time", "ddf--datapoints--lex--by--country--time", "ddf--datapoints--pop--by--country--time", "ddf--entities--geo--country"] table_name = ["gdp_per_capita", "life_expectancy", "population", "geography"] # 讀取 CSV 檔案並存入字典。 df_dict = dict() for file_name, table_name in zip(file_name, table_name): file_path = f"Data/{file_name}.csv" df = pd.read_csv(file_path) df_dict[table_name] = df
- 建立 SQLite 資料庫並匯入資料。
connection = sqlite3.connect("Data/gapminder.db") # 連線或創建 SQLite 資料庫 df_dict = data_to_dict() for k, v in df_dict.items(): v.to_sql(name=k, con=connection, index=False, if_exists="replace") # 匯入資料表 create_view()
- 建立視圖(View),整合多個資料表的數據。
drop_view_sql = "DROP VIEW IF EXISTS plotting; -- 檢查是否有plotting資料表, 若已存在則刪除" create_view_sql = """ CREATE VIEW plotting AS -- 建立虛擬資料表 SELECT g.name AS country_name, -- 國家名稱 g.world_4region AS continent, -- 洲別 gpc.time as dt_year, -- 年 gpc.gdp_pcap AS gdp_per_capita,-- 平均GDP le.lex AS life_expectancy, -- 平均壽命 p.pop AS population -- 人口數 FROM gdp_per_capita gpc JOIN geography g ON g.country = gpc.country JOIN life_expectancy le ON le.country = gpc.country AND le.time = gpc.time JOIN population p ON p.country = gpc.country AND p.time = gpc.time WHERE gpc.time < 2024; -- 篩選 2024 年以前的數據 """ # connection.execute():對資料庫執行 SQL 指令 connection.execute(drop_view_sql) # 執行 SQL 指令,如有刪除舊視圖。 connection.execute(create_view_sql) # 執行 SQL 指令,建立新視圖。 # 關閉資料庫連線,釋放資源 connection.close()